


The progress of AI models over the past two years has been remarkable, with advancements in various fields that are bringing it closer to human capabilities. This has led to the need for new tests to assess AI’s performance. Stanford University’s Institute for Human-Centered Artificial Intelligence (HAI) has recently published its seventh annual AI Index report, which comprehensively analyzes AI’s development.
This edition contains more content compared to previous editions, reflecting the rapid evolution of AI and its increasing importance in our daily lives.
The report covers a wide range of topics, including the sectors that utilize AI the most and the countries that are most concerned about job displacement due to AI. However, one of the key findings from the report is the performance of AI when compared to humans. AI has already surpassed humans in several significant benchmarks, such as image classification, basic reading comprehension, visual reasoning, and natural language inference. The speed at which AI is progressing has rendered many existing benchmarks obsolete, prompting researchers to develop new and more challenging ones.
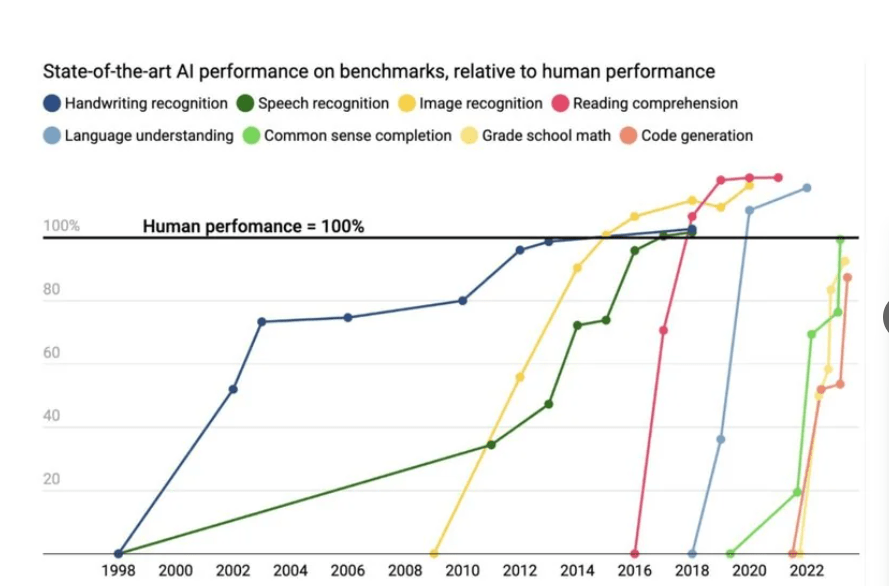
The purpose of these new tests is not to measure competence but to identify the areas where humans and AI differ and where humans still hold an advantage. Despite the advancements in AI-generated written content across various professions, there are still limitations. Large language models (LLMs) are prone to “hallucinations,” a term used to describe the presentation of false or misleading information as fact.
Last year, the extent of AI’s tendency to ‘hallucinate’ was starkly revealed to Steven Schwartz, a New York attorney who relied on ChatGPT for legal research without verifying the information. The judge overseeing the case promptly identified the fabricated legal cases in the documents generated by the AI, leading to a $5,000 (AU$7,750) fine imposed on Schwartz for his oversight. This incident garnered global attention.
HaluEval served as a standard for evaluating hallucinations. Assessments demonstrated that hallucination remains a notable challenge for many LLMs.
The issue of truthfulness poses another obstacle for generative AI. The latest AI Index report utilized TruthfulQA as a yardstick to assess the veracity of LLMs. Comprising 817 questions on various subjects like health, law, finance, and politics, this benchmark aims to challenge common misconceptions that humans frequently misunderstand.
Upon its launch in early 2024, GPT-4 achieved the highest performance on the benchmark, scoring 0.59, nearly three times better than a GPT-2-based model tested in 2021. This significant advancement indicates the ongoing improvement of LLMs in providing accurate responses.


